Event Sourcing بخش دوم
لیست مطالب آموزشی Event Sourcing:
- بخش اول مقدمهای بر Event Sourcing
- بخش دوم آشنایی مقدماتی با ساختار داخلی Event Store
- مقایسه رویکردهای State-Oriented و State-Transition
- مزیتهای Event Sourcing
- سلام به دنیا به روش Event Sourcing
- سلام به دنیا به روش Event Sourcing-بخش دوم
- بخش هفتم Projection
- بخش هشتم ویرایش ایونت ها در EventSourcing
- بخش نهم Message، Command یا Event
آشنایی مقدماتی با ساختار داخلی Event Store
-
Event Store به عنوان یک فایل لاگ
همانطور که در پست قبلی اشاره شد، Event Store مجموعهای از الگوهای طراحی است که در نهایت به ما این امکان را میدهد که بجای نگهداری آخرین وضعیت برنامه، تمامی تغییرات رخ داده در state برنامه را نگهداری کنیم.(در مورد مزایا و چالشهایی این سبک طراحی در پستها بعدی صحبت خواهم کرد).

Event Store بصورت ساده یک فایل لاگ است که این فایل همانطور که در مثال بالا مشاهده کردید، بصورت Append-Only است، بدین معنی که هر تغییری جدید به انتهای این فایل append شده و چیزی از این فایل لاگ حذف نخواهد شد.
-
Stream
به فایل لاگی که در بالا مشاده کردید، Stream میگوییم. Stream دنبالهای از Eventها به ترتیب زمان وقوعشان است. Eventها صرفنظر از نوعشان همگی به انتهای این Stream، append میشوند.
فرض کنید وضعیت stream بصورت زیر باشد.
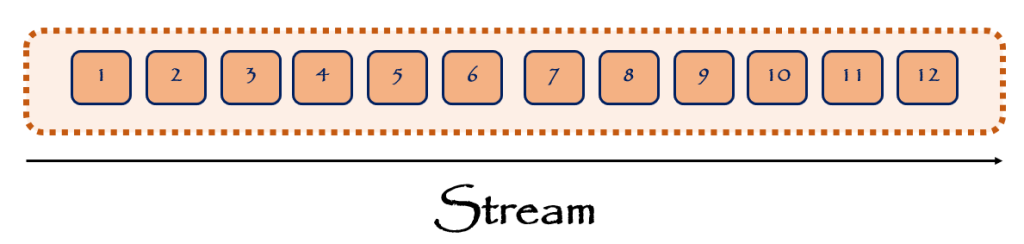
همانطور که اشاره شد، تمام Eventها صرنظر از نوعشان و اینکه در کدام بخش دومین برنامه رخداده اند، همگی در این stream، append خواهند شد. اگر نوع این Eventها از نظر اینکه آنها در کدام بخش برنامه رخ دادهاند به stream نگاه کنیم، میتوانیم stream را بصورت زیر تصور کنیم. فرض کنیم در دومین مفاهیم user و invoice را داریم. پس Eventها در نهایت توسط این user و invoice ها بوجود آمده و در نهایت در stream ذخیره شده اند.
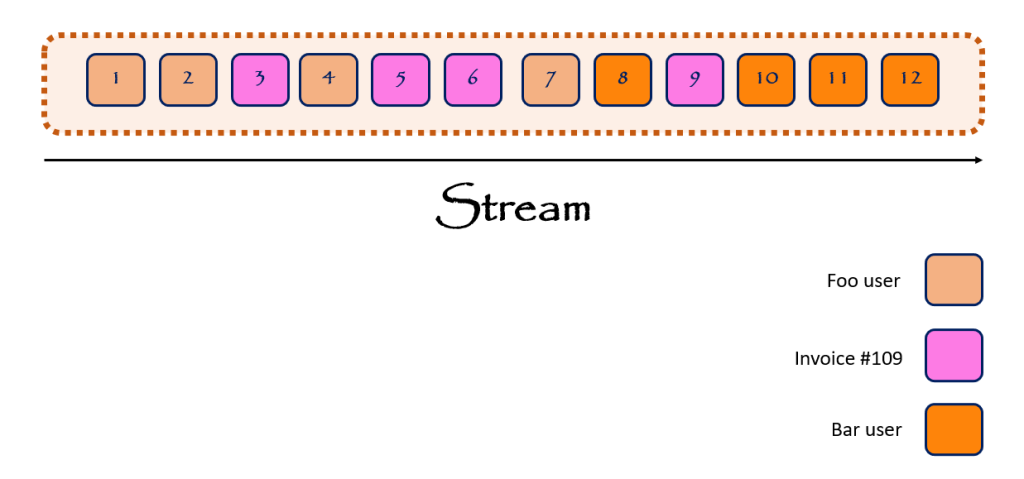
از نظر تئوری مکانیزم داخلی Event Storeها دقیقا به شکل بالا است. کاملا حیرت آور است که با همچین ساختار ذخیرهسازی سادهای میتوان Event Sourcing را پیادهسازی کرد. اما واقعیت این است که ساختار داخلی Event Storeها به همین سادگی است.
-
Stream per Aggregate
از آنجائیکه ما تمامی تغییراتی که در state برنامه اتفاق میافتد را نگه میداریم، میتوانیم براحتی انتظار داشته باشیم که با گذشت مدت زمان کوتاهی، تعداد Eventهایی که در Event Store ذخیره میشوند بسیار زیاد شوند. از طرف دیگر نگهداری کردن همه Eventها در یک فایل لاگ، میتواند rehydrate کردن آخرین وضعیت برنامه، به عنوان مثال invoice را با پیچیدگی همراه کند. در این حالت باید در جایی از برنامه لاجیکی پیادهسازی شود که Eventها را از Event Store خوانده، سپس همه آن Eventهایی که مربوط به invoice نمیباشند را رد کرده و مابقی آنها را به دومین بدهد. یا اینکه Event Storeها مکانیزمی برای گرفتن کوئری بر روی Stream داشته باشند، مکانیزمی که نیازمند زدن کوئری بر روی اطلاعات موجود در Eventها است. میدانیم که این فرآیند میتواند بسیار بسیار پیچیده باشد. چرا که Eventها بصورت serialize شده در stream نگه داشته میشوند، و stream از جزئیات داخلی این eventها کاملا بی خبر است. راجع به این موضوع در پستهای بعدی مفصلتر صحبت خواهم کرد.
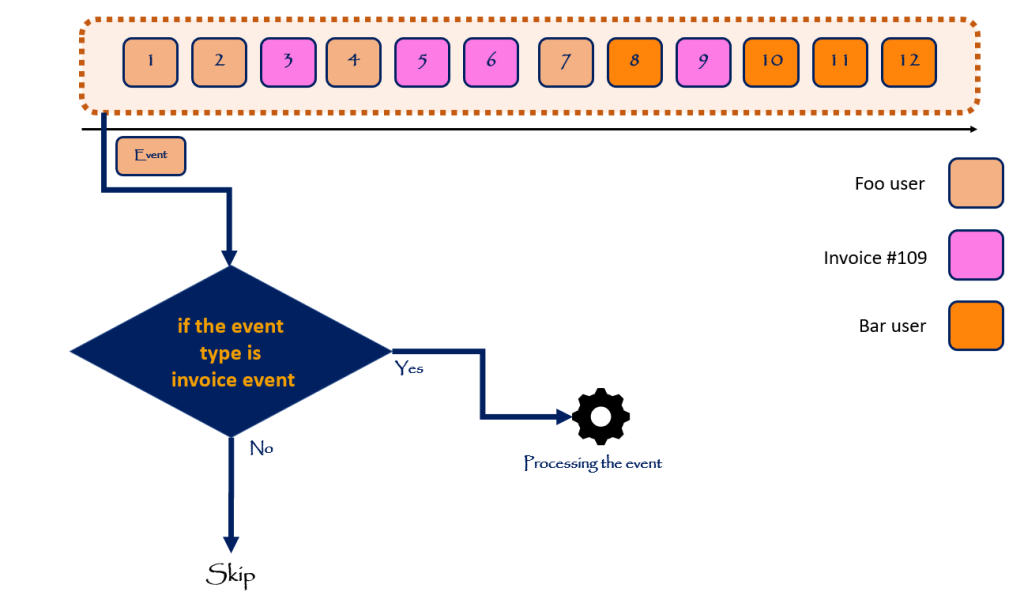
جهت غلبه بر این چالشها و پیچیدگیها، اکثر Event Store ها بجای داشتن فقط یک Stream بزرگ، چندین Stream به ازای هر aggregate دارند.
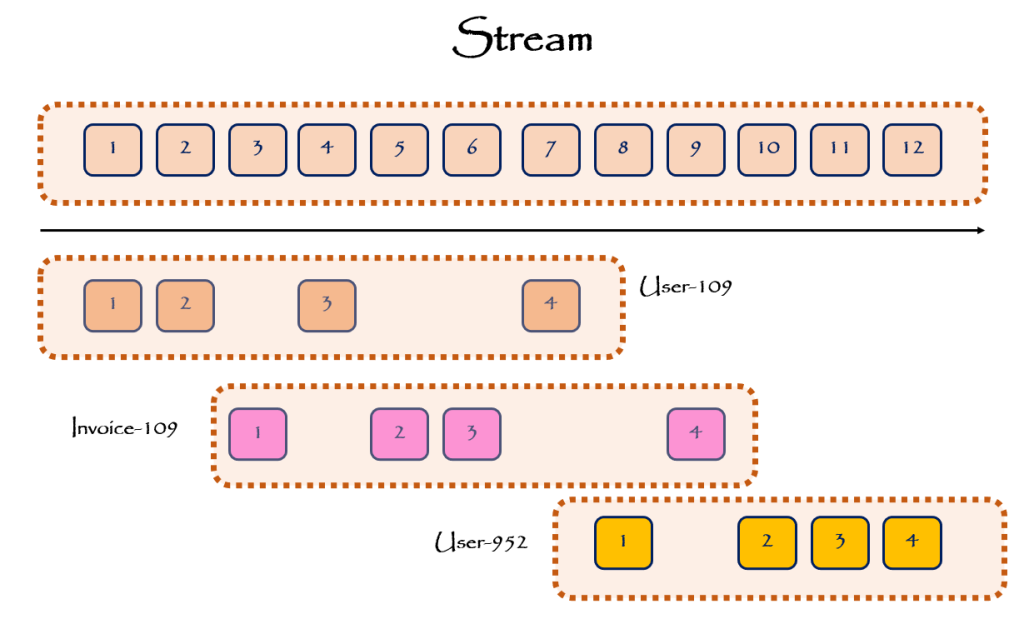
همانطور که در تصویر بالا مشاهده میکنیم سه stream به اسمهای User-109، Invoice-109 و User-952 در مثال بالا وجود دارد. با اینکار ضمن اینکه از بزرگ شدن بیش از حد stream تا حدودی جلوگیری میکنیم، پیچیدگیهای اشاره شده برای هندل کردن Eventها را نیز از بین میبریم.
هر کدام از این streamها میتوانند در یک فایل جداگانه در دیسک ذخیره شوند. مکانیزم ذخیره سازی و append کردن همچنان بسیار بسیار ساده است.
Event Storeها برای داشتن تعداد بسیار بسیار بالایی از stream ها بهینه شدهاند.
همانطور که مشاهده میکنید ما به ازای هر instance از هر آبجکت در دومین، یک stream خواهیم داشت.
-
مقایسه مکانیزم ذخیره سازی Event Store با RDBMS
میتوانیم به stream به اینصورت نگاه کنیم، که به ازای هر instance از یک user در دومین یک stream خواهیم داشت. اما در صورتی که آخرین وضعیت برنامه را فقط نگه داریم و از یک RDBMS استفاده کنیم، هر instance از user در دومین، به یک row در جدول user خواهیم داشت. پس میتوانیم اینطور نتیجه بگیریم که: هر row از یک جدول تبدیل به یک stream خواهد شد.
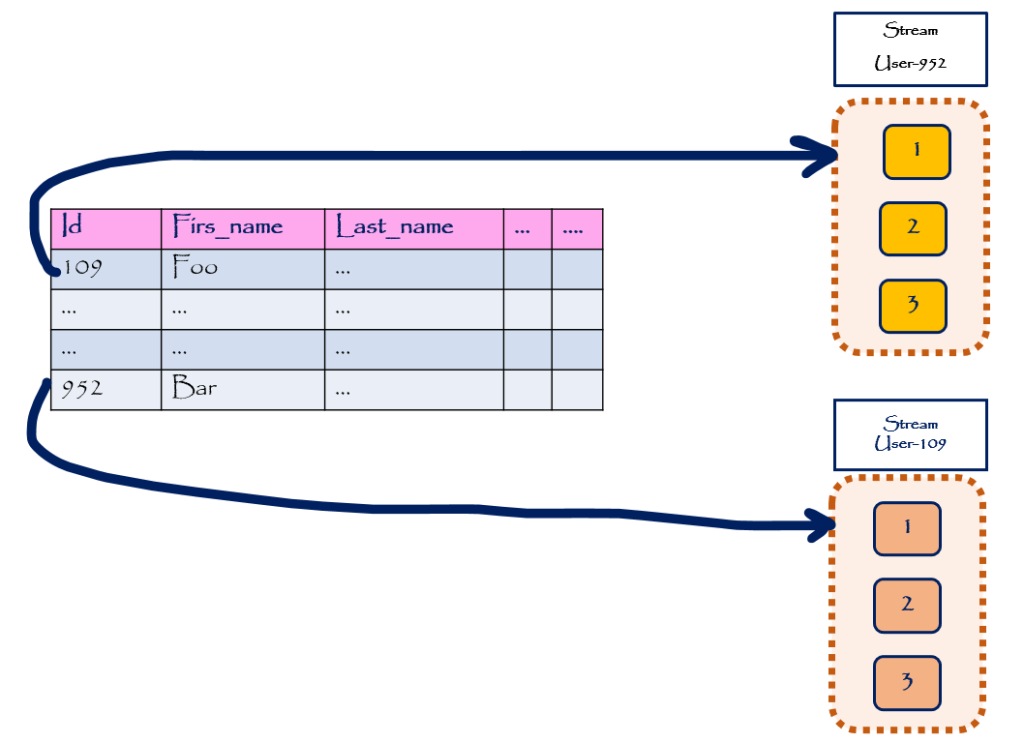
البته این نگاشت همیشه یک به یک نیست و همیشه نمیتوان اینطور در نظر گرفت که هر row از یک جدول تبدیل به یک stream خواهد شد. آبجکتهای طراحی شده در دومین یک برنامه، تشکیل یک Directed graph میدهند. وقتی این graph رو به ساختار tabular یک RDBMS نگاشت میکنیم بدلیل ماهیت ارتباطی در RDBMS که در نهایت یک Relational algebra در سطح دیتابیس تشکیل میدهند، ما معمولا نمیتوانیم یک گراف از آبجکتها که ارتباط aggregation با هم دارند و بدون همدیگر بدون معنی هستند را به یک جدول نگاشت کنیم. این چالش به Object–relational impedance mismatch نیز معروف است.
به عنوان مثال یک سند حسابداری یا Financial Transaction را در نظر بگیرید. این سند حسابداری دارای یکسری آرتیکل با Transaction Entry است. این آرتیکلها بدون سند معنایی ندارند. در حقیقت ارتباط بین آنها از نوع aggregation است و نه association. اگر بخواهیم سند را به ساختار یک RDBMS نگاشت کنیم، از آنجایی که میدانیم یک ارتباط یک به چند بین سند و آرتیکلها برقرار است، پس این ارتباط را از طریق افزودن یک کلید خارجی به جدول آرتیکل که به جدول سند اشاره میکند، برقرار میکنیم.
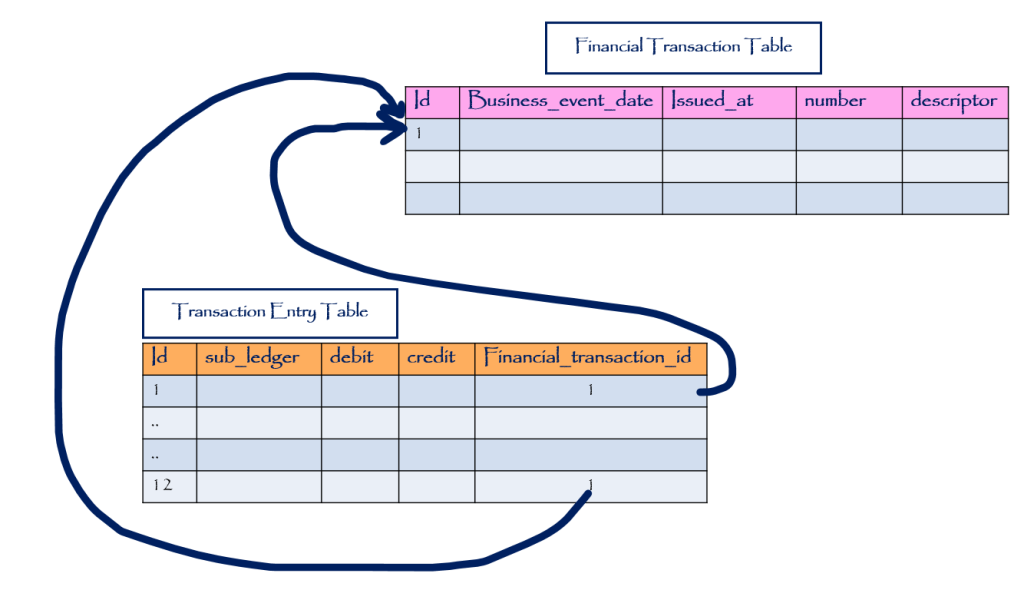
همانطور که در مثال بالا مشاهده میکنید، نمیتوان گفت که هر row از جدول transaction entry به یک stream در event store نگاشت خواهد شد. در حقیت این جدول نگاشت مستقیمی به هیچ streamای نخواهد داشت. بجای آن جدول transaction entry به stream مربوط به سند حسابداری با شماره ۱ نگاشت خواهد شد.
-
Index Stream
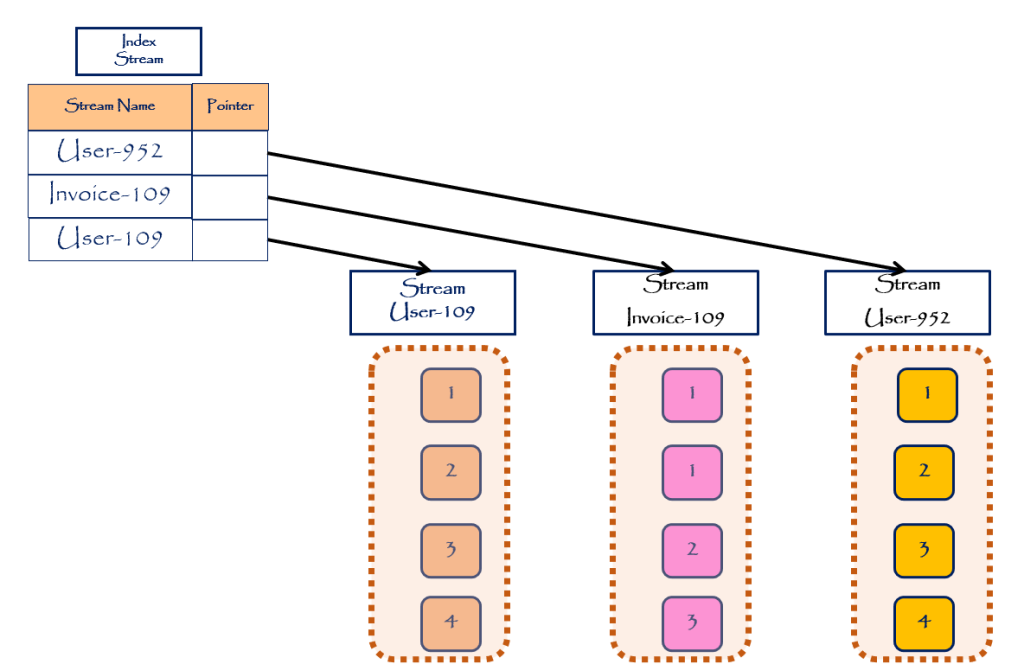
با داشتن یک دوجین از Streamها در Event Stream در صورتی که بخواهیم تمامی Eventهای یک Stream را لود کنیم، یافتن فایل مربوط به آن Stream جهت لود کردن Eventها، میتواند یک چالش بزرگ باشد. به همین دلیل در Event Storeها یک Stream سیستمی به اسم Index Stream وجود دارد. Index Stream در حقیقت یک دیکشنری شامل نام Stream و یک پوینتر آدرس، به محل آن Stream است.
-
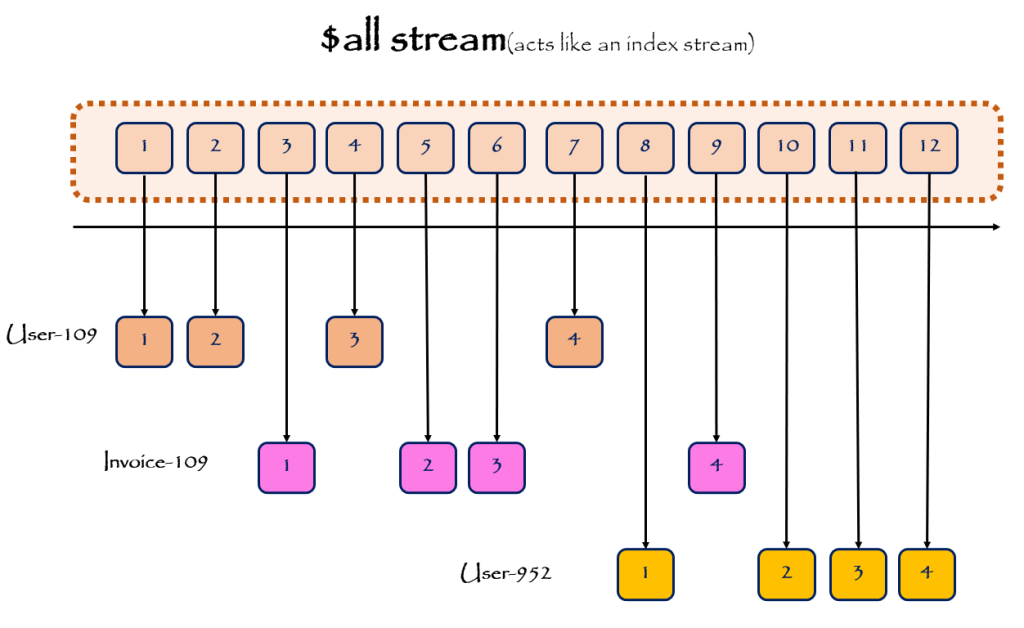
$all Stream
The EventStoreDB یک Stream سیستمی به اسم $all دارد. تمامی Eventهایی که به هر نحوی در هر کدام از Streamها append میشوند، بصورت اتوماتیک نسخهای از آن نیز در این Stream ذخیره میشود. Streamهای سیستمی شبیه $all توسط مکانیزم projection ایجاد میشود. در حقیت یک projector وجود دارد که Eventها را به یک $all، project میکند. (در مورد projection در Event Sourcing در ادامه این سری از پستهای وبلاگی مفصل صحبت خواهم کرد.).
در مورد $all stream و همینطور سایر streamهای سیستمی در The EventStoreDB در پست دیگری با جزئیات بیشتری صحبت خواهم کرد.
پایان بخش دوم
ثبت نام دوره جامع Domain Driven Design و Event Sourcing